Dear visitor who can read English
This page is a page translated automatically by Google AJAX Language API.
Please comment to this page if you could not understand. A PERSON will review this page .
I think that you will be able to understand this page later. Please give a little time to us.
Best regards,
This site is support & information site of WEB,and Software. This site might help you that create software or Web Site…perhaps?[:]
Description:
And has been the site management and maintenance, the site offline, if you want.
And renewal of the site, and the verification of the rival site.
When that, Wget, a little may help.
WGet, officially, "GNU Wget" is called.
The bottom line, GNU project in a single artifact, of course, GNU is provided by the license.
Download tools, curl, aria2 there.
Wget one.
Recursive Wget download of one of the main features of the site (the site download all the HTML files all follow the links to the file).
These features, curl has some features as well.
GUI with the curl in the famous download tool, GetLeft.
If no request is fine, if you want to download an entire site, GetLeft think is better.
Wget specified conditions is very small compared to.
Wget, you can use it, you'll see that it is considered good.
(Some may Maniac orientation) robot.txt and they recognize it, blindly, and avoid the devastation of another site.
In addition, GUI has been created in other versions of open source projects, most (as far as I know all), Wget They can be set as a parameter of the graphics in the GUI running is going on.
(FUREMASU the end of the article.
)
※ This is, C # (2008) it has been developed,. Net may require the latest.
The authors environment, C # (2008) it contains, ZIP extraction was the only work, not in such environment, run the installation from the installer, if you do not work, below. net please try to download.
(In most cases, trying to download something, but you need automatically.
)
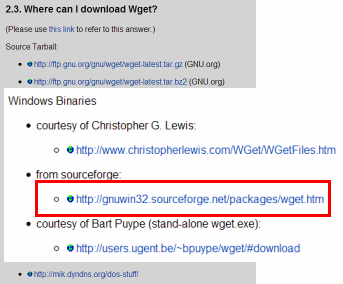
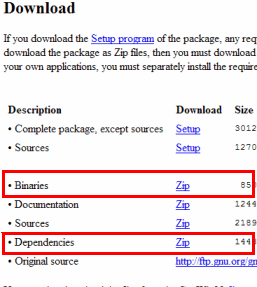
Wget destination site, wget-1.11.4-1-bin.zip, wget-1.11.4-1-dep.zip 2 and download the files.
(In some versions, the file name may be different.
)
Once downloaded, wget-1.11.4-1-bin.zip, wget-1.11.4-1-dep.zip to extract to the same directory.
This installation is complete.
Let's use
Start the command prompt, wget-1.11.4-1-bin.zip, wget-1.11.4-1-dep.zip directory where you extracted the \ bin and then move the current.
(Extracting the destination directory, bin, you should have a directory that is created.
)
If the power to help, and can be installed correctly.
If you do not output, check for errors on the steps again, please run.
The unzipped directory%% \ bin Please check the following files exist under.
libeay32.dll
libiconv2.dll
libintl3.dll
libssl32.dll
wget.exe
A man, if it fails to unpack, you may be extracting the wrong destination.
You may surprise becase there are too many parameters .
But you will be able to understand why this command have too many parameters after you read all detail of parameter.
Let's run a simple example.
The following is how you download the logo file on this site.
page1.html and image files that require the CSS file, and download all the audio files.
-K, so that even if you specify a page on the local disk (offline) to change the link so you can refer to.
So, In closing, GUI version of Let's VisualWget use.
Try VisualWget
Download from the destination, and download.
As also described earlier, this, C # (2008) it has been developed by your environment, ZIP and may only good file,The environment of .NET might be necessary.
See the description below (please see the Overview section), please install.
If you can not judge , first, from the first download, download the installer file, and then try to install.
If work is above. NET Please download and install the Microsoft environment.
This is, C # (2008) it has been developed,. Net may require the latest.
The authors environment, C # (2008) it contains, ZIP extraction was the only work, not in such environment, run the installation from the installer, if you do not work, below. net please try to download.
(In most cases, trying to download something, but you need automatically.
)
First, run the installation VisualWget.exe.
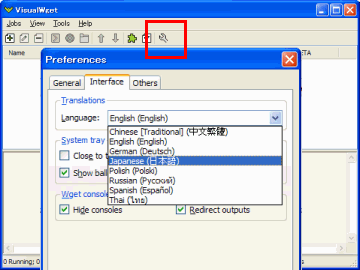
It has been like this in English, then switch to the Japanese.
Click the button to the right of the toolbar.
Screen "Language" to "Japanese", "OK" to switch to Japanese and click the button.
Usage is simple, "new job" ([file]
- [New jobs]
) Specify the sites to download now.
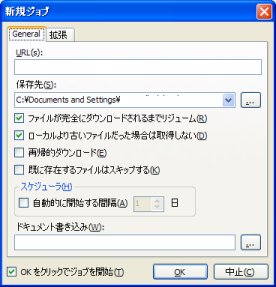
The following screen appears.
Left is a basic parameter.
Designated sites, and the output file you downloaded.
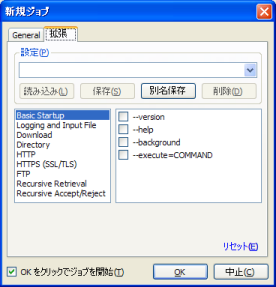
The right, Wget you can set to screen a set of detailed parameters.
(It is better if I have the parameter displayed in the Japanese category.
)
"OK" in the immediate run.
"OK" If you do not want to be spontaneous, if you want to run at a later time, "OK" button on the left "OK-click the Start Jobs" check.
If you want to do it later, should be added to the list of job-center of the screen to display the same screen and double-click the screen above.
Now, "OK-click the Start Jobs" You can not check that box, "OK" in the immediate run.
Wget if you understand the meaning of the parameters, the GUI is easy, if not, other than the simple use the "Advanced" tab screen will be low.
But rather than go on the command line, I think many people feel comfortable in, it will be easy to store configuration information files, this is it, I could.

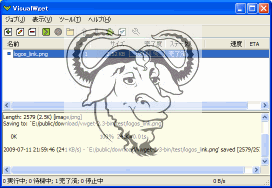 Description:
Description:
Leave a Reply