Wgetを使ってサイトのまるごとダウンロード
概要:
サイトの管理やメンテナンスを行っていると、サイトをオフラインで、見たいときがあります。サイトのリニューアルや、ライバルサイトの検証などです。
そんなときに、Wgetは、少しだけ、手助けをしてくれるかもしれません。
WGetは、正式には、"GNU Wget"と呼ばれます。要は、GNUプロジェクトの1つの成果物で、当然、GPLライセンスで提供されているものです。
ダウンロードのツールは、curl、aria2などあります。その1つにWgetがあります。Wgetの大きな特徴の一つにサイトの再帰的ダウンロード
(サイトのHTMLファイルにあるリンクをたどって全てのファイルをダウンロードすること)があります。このような機能は、curlにも一部の機能を持っています。
curlを使ったGUIのダウンロードのツールの内で有名なのが、
GetLeftです。
もし、細かい要望がなく、サイトを丸ごとダウンロードしたい場合は、
GetLeftの方が良いと思います。
指定する条件がWgetに比べれば非常に少ないからです。
Wgetは、使えば使うほど、良く考えられていることがわかります。(少し、マニアック向きかもしれません)
robot.txtの認識もしてくれるので、むやみに、他人のサイトを荒らすことも避けられます。
また、GUI版も他のオープンソースプロジェクトで作成されています。しかし、ほとんどが(筆者が知っている限りでは全て)、Wgetのパラメータをそのまま設定できるようにしていて、
実行中の状況をGUIでグラフィックでみせているもので、不親切なGUIアプリケーションです。(記事の最後にふれます。)
※Wgetのパラメータについて、ある程度の知識がないと使えないという意味で
不親切なGUIアプリケーションと言う表現をしています。そのソフトウェア自体は、決して悪いものではありませんので誤解がありませんようお願い致します。
※これは、C#(2008)で開発されていますので、.netの最新が必要かもしれません。
筆者の環境には、C#(2008)が入っていますので、ZIPの解凍だけで動作しましたが、そのような環境にない方は、インストーラからインストールを実行して、動作しないようであれば、
以下の.net環境をダウンロードしてみてください。(ほとんどの場合は、自動で必要なものをダウンロードしようとするとは思いますが・・・。)
インストールする
先のWgetダウンロードサイトから、wget-1.11.4-1-bin.zip,wget-1.11.4-1-dep.zipの2つのファイルをダウンロードします。(バージョンによっては、ファイル名が異なるかもしれません。)
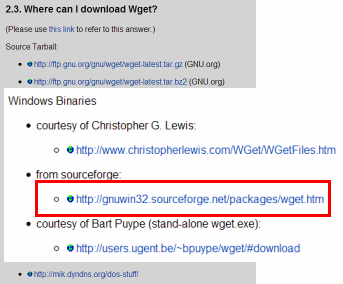
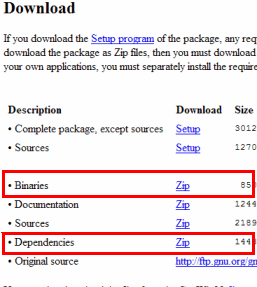
ダウンロードを終えたら、wget-1.11.4-1-bin.zip,wget-1.11.4-1-dep.zipを同じディレクトリへ解凍します。
インストールはこれで終了です。
使ってみましょう
コマンドプロンプトを起動して、wget-1.11.4-1-bin.zip,wget-1.11.4-1-dep.zipを
解凍したディレクトリ\bin にカレントを移動します。
(解凍先のディレクトリに、
binというディレクトリが作成されているはずです。)
%解凍したディレクトリ%\bin> wget -h
SYSTEM_WGETRC = c:/progra~1/wget/etc/wgetrc
syswgetrc = %解凍したディレクトリ%/etc/wgetrc
GNU Wget 1.11.4, 非対話的ネットワーク転送ソフト
使い方: wget [オプション]... [URL]...
長いオプションで不可欠な引数は短いオプションでも不可欠です。
スタートアップ:
-V, --version バージョン情報を表示して終了する
-h, --help このヘルプを表示する
-b, --background スタート後にバックグラウンドに移行する
-e, --execute=COMMAND .wgetrc'形式のコマンドを実行する
ログと入力ファイル:
-o, --output-file=FILE ログを FILE に出力する
-a, --append-output=FILE メッセージを FILE に追記する
-d, --debug デバッグ情報を表示する
-q, --quiet 何も出力しない
-v, --verbose 冗長な出力をする (デフォルト)
-nv, --no-verbose 冗長ではなくする
-i, --input-file=FILE FILE の中に指定された URL をダウンロードする
-F, --force-html 入力ファイルを HTML として扱う
-B, --base=URL 相対 URL(-F -i 使用時) のベース URL を指定する
ダウンロード:
-t, --tries=NUMBER リトライ回数の上限を指定 (0 は無制限).
--retry-connrefused 接続を拒否されてもリトライする
-O, --output-document=FILE FILE に文書を書きこむ
-nc, --no-clobber 存在しているファイルをダウンロードで上書きしない
-c, --continue 部分的にダウンロードしたファイルの続きから始める
--progress=TYPE 進行表示ゲージの種類を TYPE に指定する
-N, --timestamping ローカルにあるファイルよりも新しいファイルだけ取得する
-S, --server-response サーバの応答を表示する
--spider 何もダウンロードしない
-T, --timeout=SECONDS 全てのタイムアウトを SECONDS 秒に設定する
--dns-timeout=SECS DNS 問い合わせのタイムアウトを SECS 秒に設定する
--connect-timeout=SECS 接続タイムアウトを SECS 秒に設定する
--read-timeout=SECS 読み込みタイムアウトを SECS 秒に設定する
-w, --wait=SECONDS ダウンロード毎に SECONDS 秒待つ
--waitretry=SECONDS リトライ毎に 1 - SECONDS 秒待つ
--random-wait ダウンロード毎に 0 - 2*WAIT 秒待つ
--no-proxy プロクシを使わない
-Q, --quota=NUMBER ダウンロードするバイト数の上限を指定する
--bind-address=ADDRESS ローカルアドレスとして ADDRESS (ホスト名か IP) を使う
--limit-rate=RATE ダウンロード速度を RATE に制限する
--no-dns-cache DNS の問い合わせ結果をキャッシュしない
--restrict-file-names=OS OS が許しているファイル名に制限する
--ignore-case ファイル名/ディレクトリ名の比較で大文字小文字を無視する
-4, --inet4-only IPv4 だけを使う
-6, --inet6-only IPv6 だけを使う
--prefer-family=FAMILY 指定したファミリ(IPv6, IPv4, none)で最初に接続する
--user=USER ftp, http のユーザ名を指定する
--password=PASS ftp, http のパスワードを指定する
ディレクトリ:
-nd, --no-directories ディレクトリを作らない
-x, --force-directories ディレクトリを強制的に作る
-nH, --no-host-directories ホスト名のディレクトリを作らない
--protocol-directories プロトコル名のディレクトリを作る
-P, --directory-prefix=PREFIX ファイルを PREFIX/ 以下に保存する
--cut-dirs=NUMBER リモートディレクトリ名の NUMBER 階層分を無視する
HTTP オプション:
--http-user=USER http ユーザ名として USER を使う
--http-password=PASS http パスワードとして PASS を使う
--no-cache サーバがキャッシュしたデータを許可しない
-E, --html-extension HTML 文書は .html' 拡張子で保存する
--ignore-length Content-Length' ヘッダを無視する
--header=STRING 送信するヘッダに STRING を追加する
--max-redirect ページで許可する最大転送回数
--proxy-user=USER プロクシユーザ名として USER を使う
--proxy-password=PASS プロクシパスワードとして PASS を使う
--referer=URL Referer を URL に設定する
--save-headers HTTP のヘッダをファイルに保存する
-U, --user-agent=AGENT User-Agent として Wget/VERSION ではなく AGENT を使う
--no-http-keep-alive HTTP の keep-alive (持続的接続) 機能を使わない
--no-cookies クッキーを使わない
--load-cookies=FILE クッキーを FILE から読みこむ
--save-cookies=FILE クッキーを FILE に保存する
--keep-session-cookies セッションだけで用いるクッキーを保持する
--post-data=STRING POST メソッドを用いて STRING を送信する
--post-file=FILE POST メソッドを用いて FILE の中味を送信する
--content-disposition Content-Disposition ヘッダがあれば
ローカルのファイル名として用いる (実験的)
--auth-no-challenge サーバからのチャレンジを待たずに、
Basic認証の情報を送信します。
HTTPS (SSL/TLS) オプション:
--secure-protocol=PR セキュアプロトコルを選択する (auto, SSLv2, SSLv3, TLSv1)
--no-check-certificate サーバ証明書を検証しない
--certificate=FILE クライアント証明書として FILE を使う
--certificate-type=TYPE クライアント証明書の種類を TYPE (PEM, DER) に設定する
--private-key=FILE 秘密鍵として FILE を使う
--private-key-type=TYPE 秘密鍵の種類を TYPE (PEM, DER) に設定する
--ca-certificate=FILE CA 証明書として FILE を使う
--ca-directory=DIR CA のハッシュリストが保持されているディレクトリを指定する
--random-file=FILE SSL PRNG の初期化データに使うファイルを指定する
--egd-file=FILE EGD ソケットとして FILE を使う
FTP オプション:
--ftp-user=USER ftp ユーザとして USER を使う
--ftp-password=PASS ftp パスワードとして PASS を使う
--no-remove-listing .listing' ファイルを削除しない
--no-glob FTP ファイル名のグロブを無効にする
--no-passive-ftp "passive" 転送モードを使わない
--retr-symlinks 再帰取得中に、シンボリックリンクでリンクされた先のファイルを取得する
--preserve-permissions リモートファイルのパーミッションを保存する
再帰ダウンロード:
-r, --recursive 再帰ダウンロードを行う
-l, --level=NUMBER 再帰時の階層の最大の深さを NUMBER に設定する (0 で無制限)
--delete-after ダウンロード終了後、ダウンロードしたファイルを削除する
-k, --convert-links HTML 中のリンクをローカルを指すように変更する
-K, --backup-converted リンク変換前のファイルを .orig として保存する
-m, --mirror -N -r -l 0 --no-remove-listing の省略形
-p, --page-requisites HTML を表示するのに必要な全ての画像等も取得する
--strict-comments HTML 中のコメントの処理を厳密にする
再帰ダウンロード時のフィルタ:
-A, --accept=LIST ダウンロードする拡張子をコンマ区切りで指定する
-R, --reject=LIST ダウンロードしない拡張子をコンマ区切りで指定する
-D, --domains=LIST ダウンロードするドメインをコンマ区切りで指定する
--exclude-domains=LIST ダウンロードしないドメインをコンマ区切りで指定する
--follow-ftp HTML 文書中の FTP リンクも取得対象にする
--follow-tags=LIST 取得対象にするタグ名をコンマ区切りで指定する
--ignore-tags=LIST 取得対象にしないタグ名をコンマ区切りで指定する
-H, --span-hosts 再帰中に別のホストもダウンロード対象にする
-L, --relative 相対リンクだけ取得対象にする
-I, --include-directories=LIST 取得対象にするディレクトリを指定する
-X, --exclude-directories=LIST 取得対象にしないディレクトリを指定する
-np, --no-parent 親ディレクトリを取得対象にしない
バグ報告や提案は<bug-wget@gnu.org>へ
%解凍したディレクトリ%\bin>
|
このようにヘルプが出力されれば、正しくインストールができています。
もし、出力されないようであれば、手順に誤りがないか確認の上、再度、実行してみてください。
また、%解凍したディレクトリ%\binの配下に以下のファイルが存在するかチェックしてください。
- libeay32.dll
- libiconv2.dll
- libintl3.dll
- libssl32.dll
- wget.exe
無ければ、解凍に失敗しているか、解凍先を間違っている可能性があります。
パラメータの数に驚きますが、一つ一つ確認すると、先のヘルプが全てです。
では、単純な例を実行してみましょう。
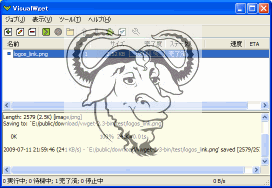
以下は、このサイトのロゴファイルをダウンロードした様子です。
%解凍したディレクトリ%\bin> wget http://www.example.com/images/logo.png
SYSTEM_WGETRC = c:/progra~1/wget/etc/wgetrc
syswgetrc = E:\public\download\wget-1.11.4-1-bin/etc/wgetrc
--2009-07-11 20:54:12-- http://www.example.com/images/logo.png
www.example.com をDNSに問いあわせています... xxx.xxx.xxx.xxx
www.example.com|xxx.xxx.xxx.xxx|:80 に接続しています... 接続しました。
HTTP による接続要求を送信しました、応答を待っています... 200 OK
長さ: 2579 (2.5K) [image/png]
logo.png' に保存中
100%[======================================================================================>] 2,579 --.-K/s 時間 0s
2009-07-11 20:54:13 (47.8 MB/s) - logo.png' へ保存完了 [2579/2579]
%解凍したディレクトリ%\bin>
|
非常に簡単ですね。
カレントディレクトリにlogo.pngというファイルが保存されたことと思います。
お願い:
この記事をご覧になって、Wgetをこのサイトで試すのは、止めてください。
このサイトは、非常に貧弱なサイトですので、Wgetを試されてしまうと、重たくなってしまいます。
どうかお願いいたします。
次に、色々な使い方によって、パラメータの指定の仕方を簡単に記述してみましょう。
色々な使い方
サイトを丸ごとダウンロードして、ミラーディスクを作成するコマンドの例
%解凍したディレクトリ%\bin> wget -m http://www.example.com/
|
今度は、カレントディレクトリに
www.example.comというディレクトリが作成され、そこに全てのファイルがダウンロードされます。
jpgの拡張子を持つファイルのみをサイトを丸ごとダウンロードして、ミラーディスクを作成するコマンドの例
%解凍したディレクトリ%\bin> wget -m -A.jpg http://www.example.com/
|
-A "*.jpg"'
でも同じ動作をします。また、
".gif"ファイルも含めたい場合は、カンマで続けます。
-A .jpg,.gif
のようにです。
ここには、正規表現も使えます。
-A "200[0-9].jpg"
のようにです。
これを実行すると、2000.jpg - 2009.jpg の10個のファイル名の中で、存在するもの全てダウンロードします。
-Rは、
-Aの逆で、指定された名前のファイルをダウンロードしません。
1ページに関連しているファイルを全てダウンロードするの例
%解凍したディレクトリ%\bin> wget -p -k http://www.example.com/page1.html
|
page1.htmlが必要としている画像ファイルやCSSファイル、音声ファイルなどを全てダウンロードします。
更に
-kを指定しているので、このページをローカルディスク上(オフライン)で参照できるようにリンクを変更します。
ダウンロードの実行ログをファイルへ出力するの例
%解凍したディレクトリ%\bin> wget -m http://www.example.com/ -o exec.log
|
へ、通常、画面出力される情報が出力されます。
ダウンロードの状況出力を一切止めるの例
%解凍したディレクトリ%\bin> wget -m http://www.example.com/ -q
|
通常、画面出力される情報が、一切、出力されなくなります。
さて、最後になりましたが、GUI版のVisualWgetを使ってみましょう。
VisualWgetを使ってみる
先のダウンロード先から、ダウンロードします。
先にも記述しているとおり、これは、C#(2008)で開発されていますので、皆さんの環境によっては、ZIPファイルのみで良い場合もありますし、
.NETの環境まで必要とするかもしれません。
以下の記述を参考に(概要部分も参照してください)、インストールしてください。
判らない方は、まず、先のダウンロード先から、インストーラファイルをダウンロードし、インストールしてみます。
動かない場合は、上記の.NETの環境をマイクロソフトからダウンロードしてインストールしてください。
これは、C#(2008)で開発されていますので、.netの最新が必要かもしれません。
筆者の環境には、C#(2008)が入っていますので、ZIPの解凍だけで動作しましたが、そのような環境にない方は、インストーラからインストールを実行して、動作しないようであれば、
以下の.net環境をダウンロードしてみてください。(ほとんどの場合は、自動で必要なものをダウンロードしようとするとは思いますが・・・。)
まずは、インストール先の
VisualWget.exe を実行します。
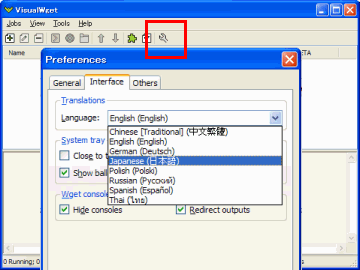
このように英語で表示されていますので、日本語へ切り替えます。
ツールバーの右のボタンをクリックします。画面の"Language"を"日本語"として、"OK"ボタンをクリックすると日本語へ切り替わります。
使い方は、簡単で、"新規ジョブ"([ファイル] - [新規ジョブ])でこれからダウンロードするサイトを指定します。
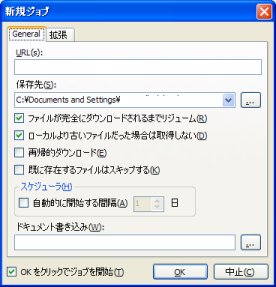
その際、以下の画面が表示されます。
左は、基本的なパラメータです。サイトの指定、ダウンロードしたファイルの出力先などです。
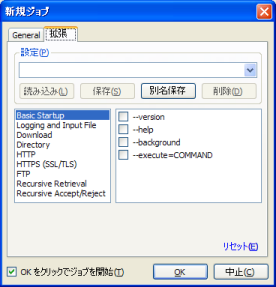
右が、Wgetのパラメータ群を細部に設定できる画面です。(パラメータのカテゴリが日本語で表示してあればもっと良いのですけどね。)
"OK"で即実行します。
"OK"で即実行したくない場合、後で実行したい場合は、"OK"ボタン左の"OKをクリックでジョブを開始"のチェックを外します。
後で実行する場合は、画面中央のリストに設定されたジョブが追加されているはずですから、ダブルクリックで上記の画面と同じ画面を表示します。
今度は、"OKをクリックでジョブを開始"というチェックボックスがありませんので、"OK"で即実行します。
Wgetのパラメータの意味を理解できていれば、このGUIは簡単ですが、そうでない場合は、単純な使い方以外、"拡張"というタブ画面を使いこなせないでしょう。
でも、コマンドラインでやるよりは、感覚的に楽な方も多いと思いますし、設定情報をファイルへ保存することも簡単にやってくれますから、これはこれで、使えると思います。
また、ここでは、wgetrcについて触れていませんが、プロキシのパラメータなどを指定することができるものです。
詳しくは、マニュアルを参照してください。
http://www.gnu.org/software/wget/manual/wget.html




コメントをどうぞ